
What Is a URL?
A uniform resource locator (URL) is the address of a specific webpage or file (such as video, image, GIF, etc.) on the internet.
It's what you type into your browser's address bar to access an online resource.
How Do URLs Work?
Here’s a quick breakdown of how URLs work:
When you type a URL into your browser's address bar, you're giving your browser specific instructions on where to go on the internet.
Once it knows that, the browser sends a request to a web server at that address. This server is a powerful computer that stores the webpage or file you're trying to access.
Once the server processes your request, it sends back the requested resource (webpage, image, video, etc.).
Your browser then displays the contents of that resource on the screen.
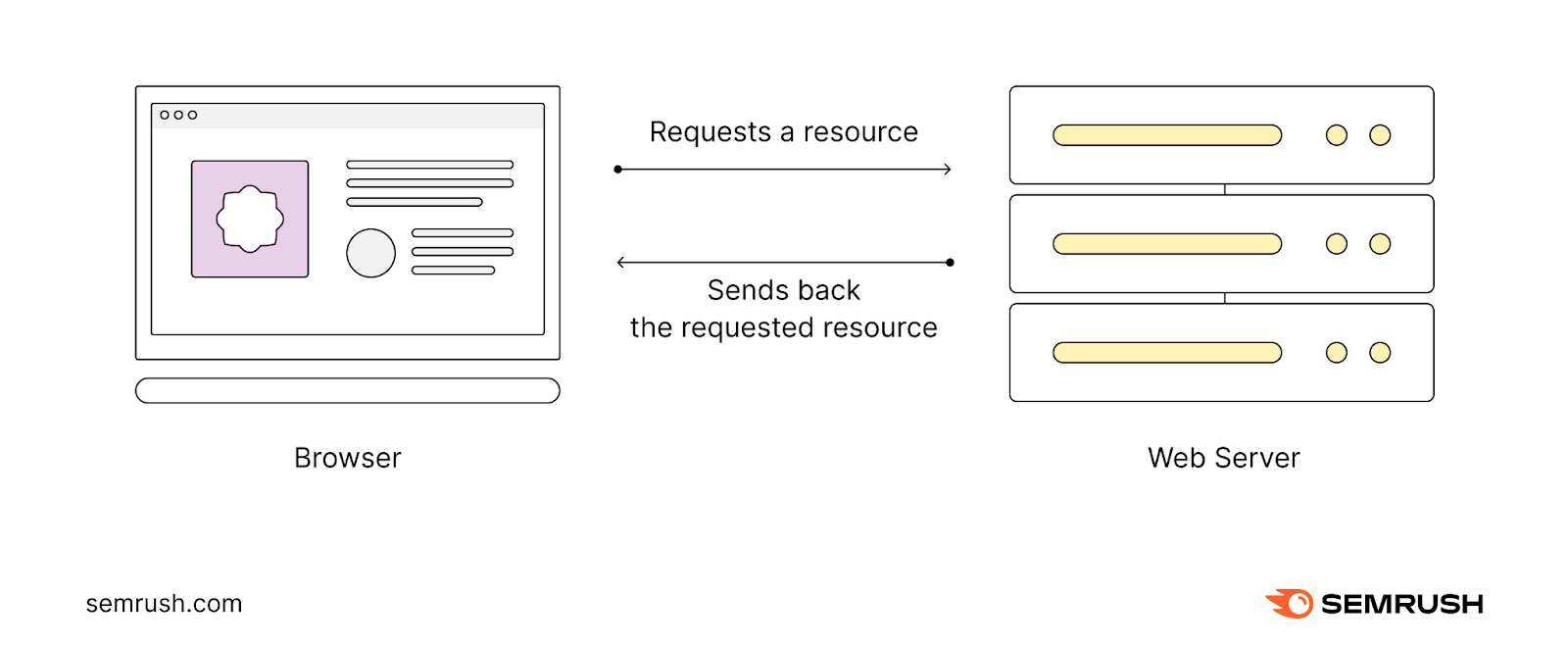
This interaction between your browser, the URL, and the web server is the fundamental process that powers the internet as we know it.
Why Are URLs Important?
A URL points your browser to the exact spot—be it a webpage or file—that you want to view.
This matters because there are billions of resources across more than a billion websites.
URLs uniquely identify each one, from your homepage to your dog’s Instagram account. And get you where you want to go.
This benefit is on the user’s side.
On the website developer’s side, URLs are equally crucial.
Developers use URLs when handling a website’s hypertext markup language (HTML).
They use URLs to create links between different pages using the anchor element (also called an <a> tag). This lets you connect webpages and allows users to navigate between them.
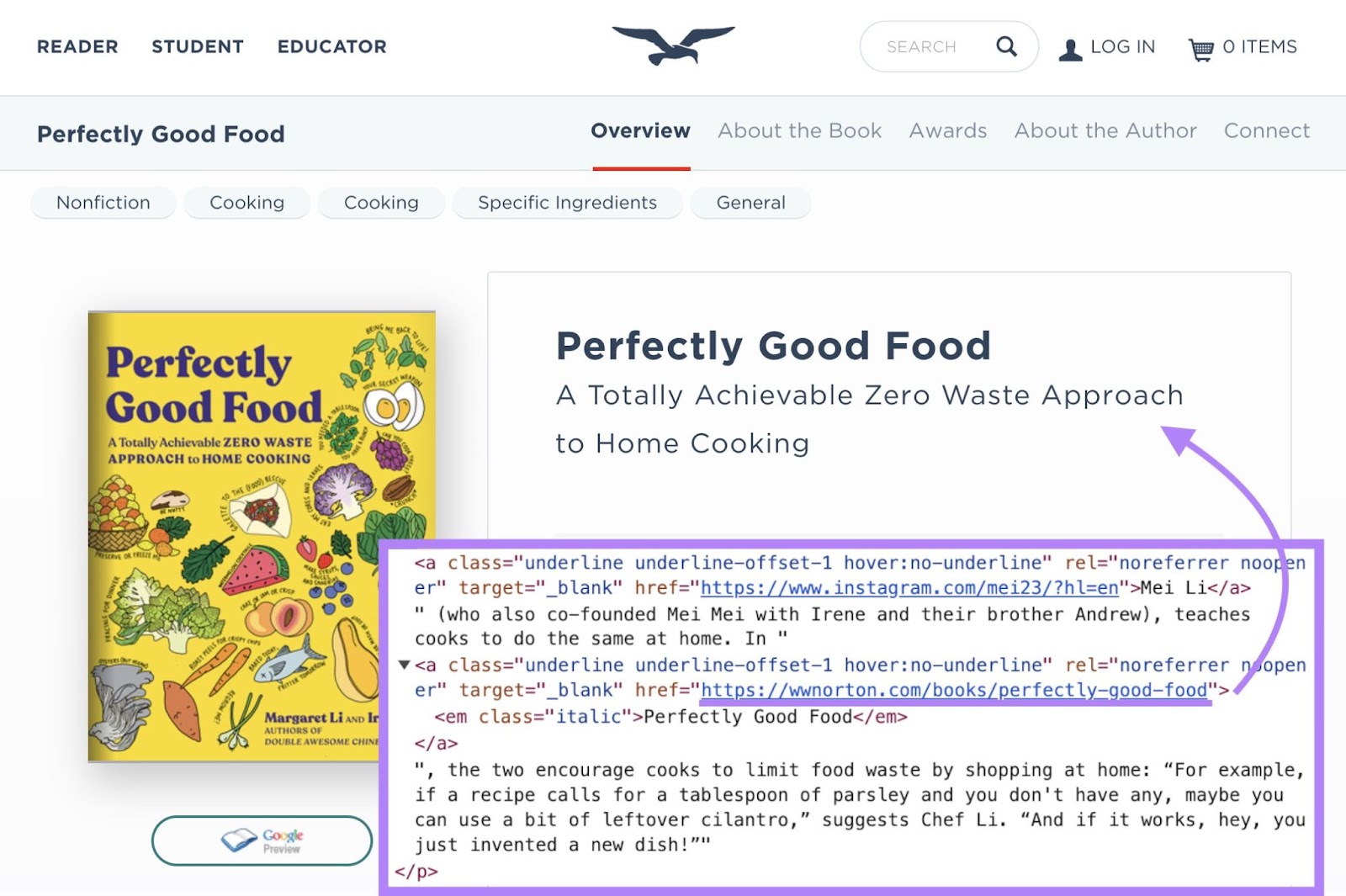
What’s more, URLs also allow separating code into distinct files that can be linked together.
So all your cascading style sheet (CSS) files, JavaScript files, and other assets can be organized cleanly. The HTML just needs to reference those URLs to pull everything together for the final webpage.
Now, let’s understand how URLs are structured.
What Are the Different Parts in URL Structure?
The structure of a URL breaks down into five distinct parts. Like this:

Scheme
The scheme is the first part of the URL. It indicates the protocol for accessing the resource.

A protocol is a set of rules for how a connection between a browser and a web server should be established.
Common schemes you might recognize are:
HTTP
Hypertext transfer protocol (HTTP) is a standard protocol for establishing a connection between a browser and a web server.
When you enter a URL with the “http” prefix, your browser sends a request to the server to retrieve the resource specified in the URL.
The server then responds by sending back the requested resource if it’s available.
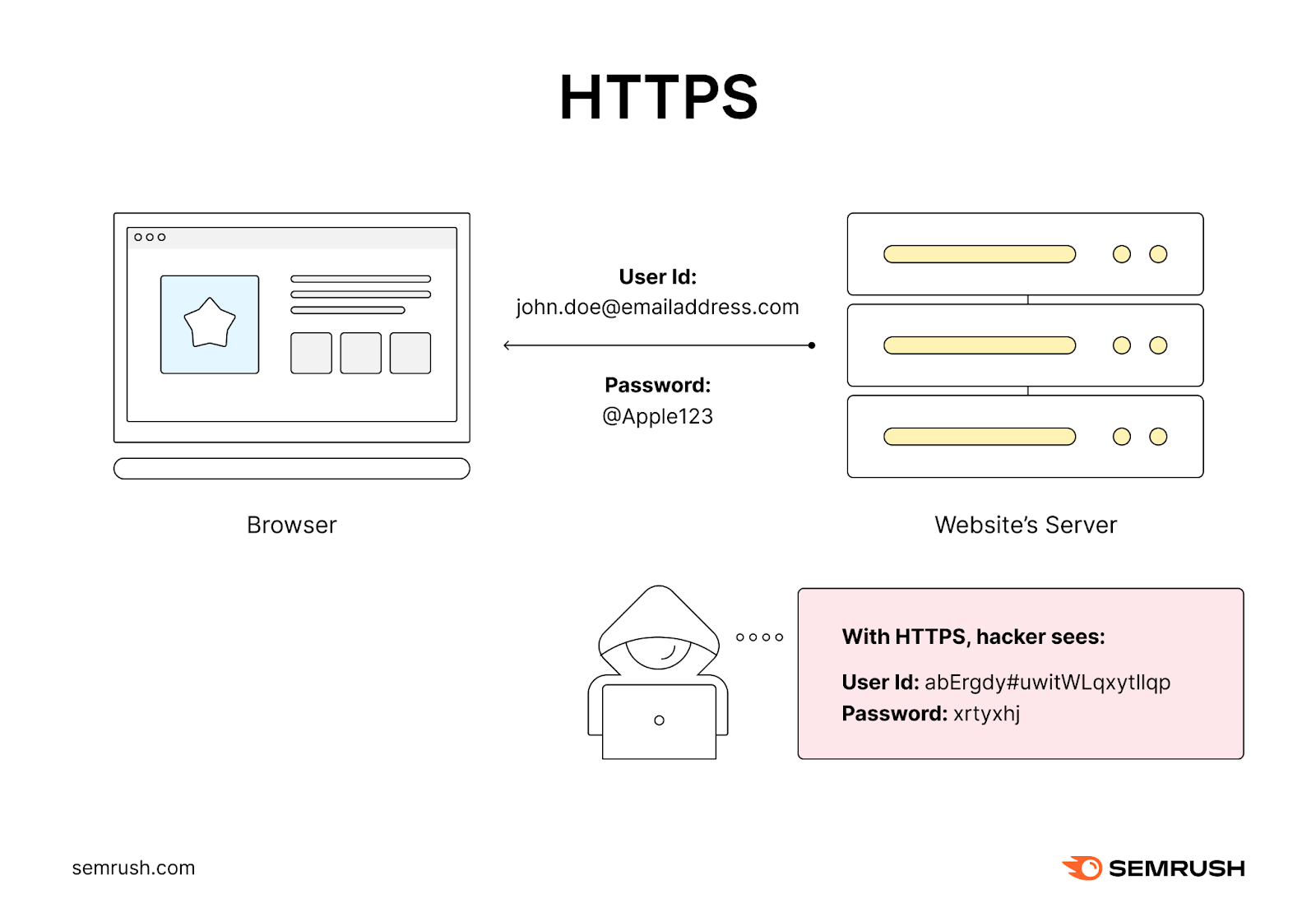
But this connection isn’t secure. Which means anyone can intercept and read the data.
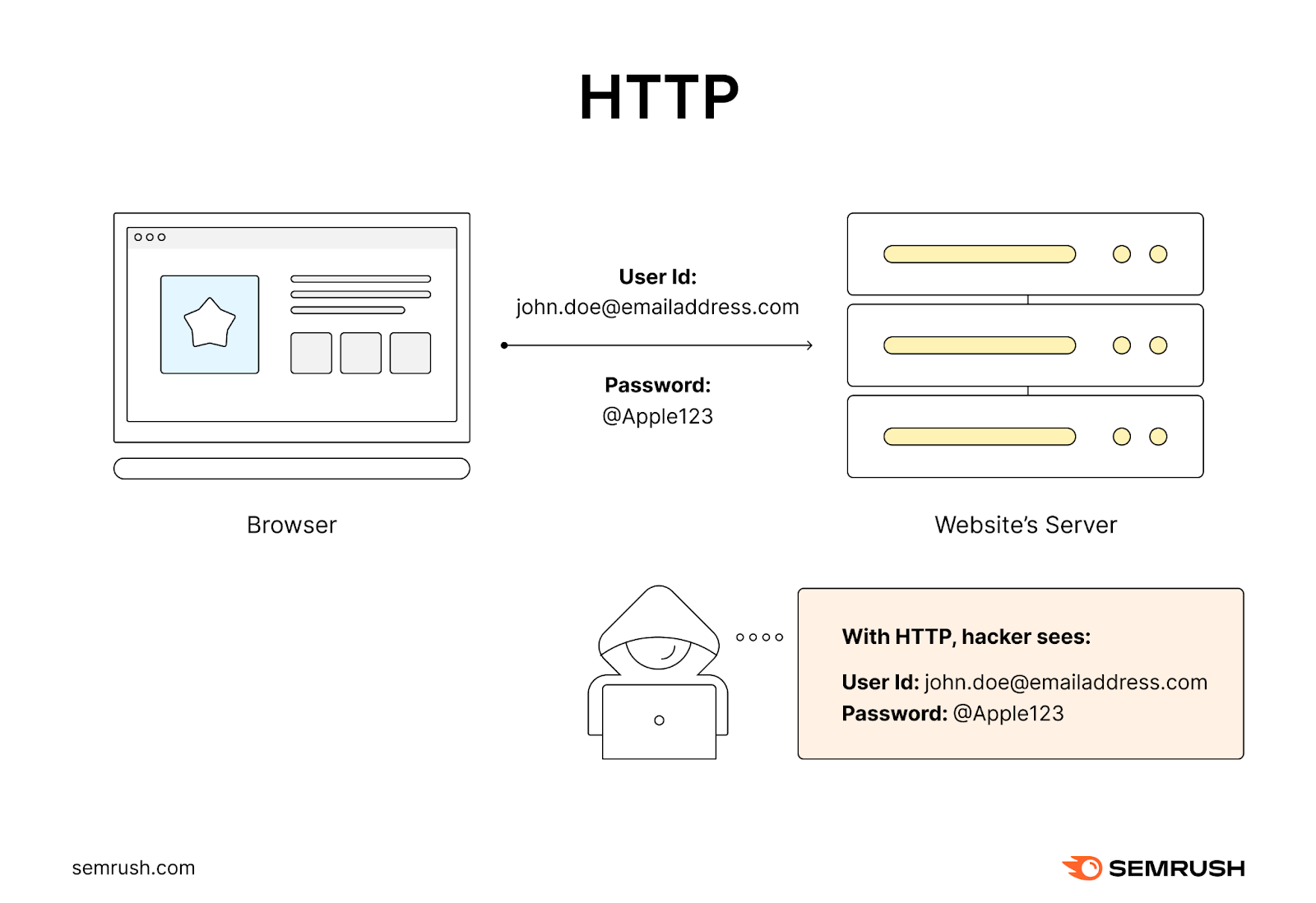
This creates a serious security loophole. That’s why websites (and search engines) prefer hypertext transfer protocol secure (HTTPS) these days.
HTTPS
This is HTTP's more secure sibling. That adds an encryption layer to your web session.
This means that any information transferred between your browser and the server is encrypted and much harder for outsiders to intercept.
Besides HTTPS, browsers can also handle other schemes like file transfer protocol (FTP) and mailto.
Further reading: HTTP vs. HTTPS: Differences, Benefits, and Migration Tips
FTP & Mailto
FTP is used for transferring files between a browser and a web server.
When you enter a URL starting with "ftp," it initiates a connection to your FTP server.
Then, you can manage your website files. Meaning you can download or upload any files you want.
Unlike HTTP and HTTPS, FTP is focused solely on the transfer of files. Not rendering webpages. And a typical FTP URL looks something like this:
ftp://ftp.host.com/The mailto scheme is used to create a hyperlink that opens the user's email client (Outlook, Gmail, etc.) to send an email.
When you click on a link with this prefix, it automatically opens your default email client and pre-populates the recipient's email address to what was specified in the URL.

This is convenient for letting users quickly send emails to contacts listed on websites without having to copy and paste their email addresses.
While not as commonly used as HTTP or HTTPS, both FTP and mailto play important roles in specific contexts.
Authority
The authority is the second part of a URL that comes after the “://” character pattern.

It tells your browser where to find the site and who it belongs to.
This part of the URL consists of four main components:
Subdomain
A subdomain is a string of letters or a complete word that appears before a URL’s first dot.

The most popular subdomain is www. It stands for world wide web, communicating that the URL is a web address.
In the past, it was common to use www. But you can omit it from your URLs if you want.
It doesn’t matter whether you use it. It all depends on your personal preference.
Domain
A domain is the name of a website. Like eBay, Expedia, or Semrush.

It’s an easy-to-remember part of the URL.
Each domain is unique. So whenever you type it in, you reference a specific website you intend to visit.
Top-Level Domain and Country-Code Top-Level Domain
The top-level domain (TLD)—also called domain extension—is the part that comes after the name of your website. Like “.com.”

You’ll come across many TLDs on the internet. Here’s a list of five of the most common ones and which kinds of websites use them:
- .com: Commercial websites
- .org: Nonprofit organizations
- .net: Software and hosting companies providing network services
- .edu: Educational institutions (universities, colleges, schools, etc.)
- .gov: Government agencies and departments
Additionally, there are country-code top-level domains (ccTLDs).
ccTLDs are two-letter domain extensions that indicate a website’s association with a specific country or territory.
Examples include:
- .uk for United Kingdom
- .de for Germany
- .cn for China
- .ca for Canada
- .in for India
- .es for Spain
- .au for Australia
- .nz for New Zealand
Websites use ccTLDs when their target audience is predominantly based in a specific country.
By using ccTLD, a website signals its connection to that location. Which can help to establish trust and credibility with users in that region.
Port
A port is the numerical identifier that specifies a particular gateway for directing traffic to your web server.

It’s like a door people pass through to visit your site.
Most of the time, you don't see port numbers in URLs because they're using standard ports. Which browsers assume by default (e.g., port 80 for HTTP and port 443 for HTTPS).
Path
The next part of the URL is the path. And it indicates the specific directions to the page (or resource) being requested on a domain.

It’s like the exact route you take to a room in a large building (the domain).
Generally, the path is made up of two parts:
Subfolder
A subfolder (also called a subdirectory) is a folder or directory located in the main directory that houses the page a user has requested.

Subfolders allow websites to organize related pages together within the domain's overall directory structure.
Like this:
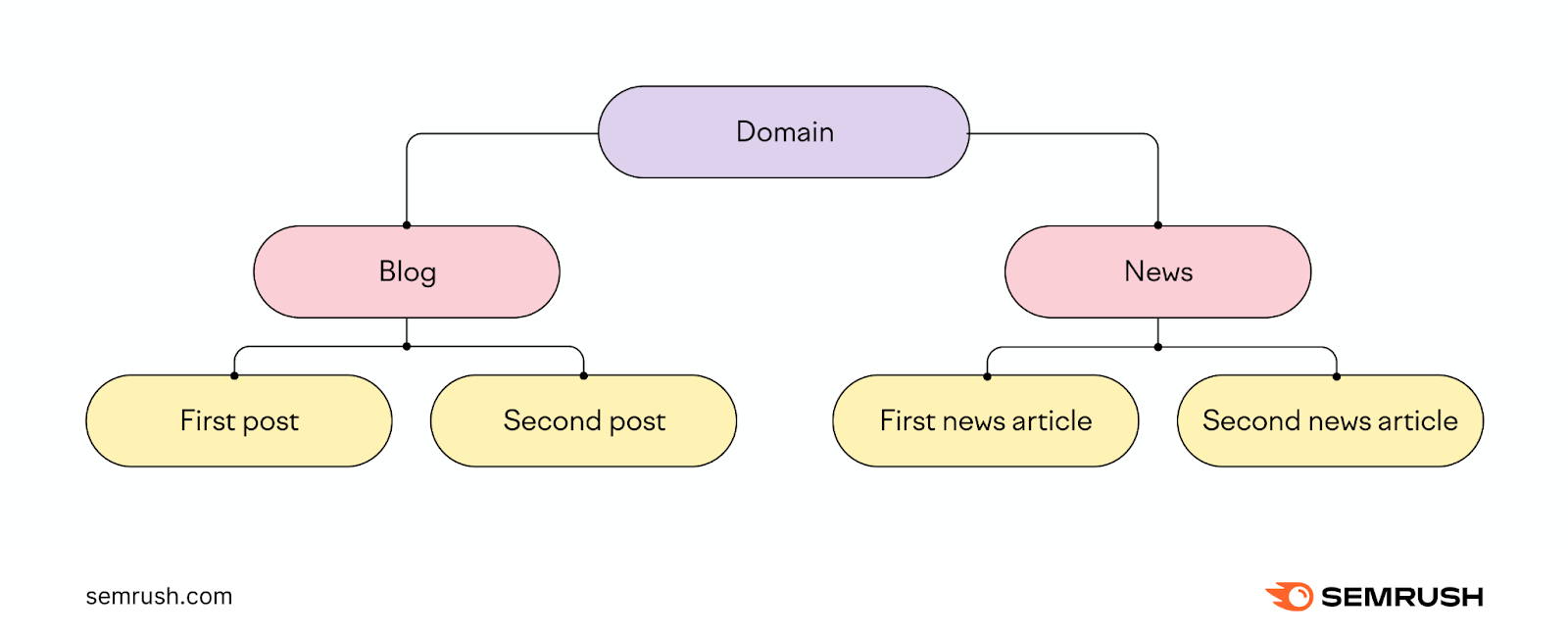
Here, "blog" and "news" are subfolders within the main domain that both organize related content.
URLs for these four pages would look something like this:
- https://www.example.com/blog/first-post
- https://www.example.com/blog/second-post
- https://www.example.com/news/first-news-article
- https://www.example.com/news/second-news-article
Slug
A slug is the last segment of the path that identifies a particular page. Often, in a human-readable format.

It helps users understand where exactly they are on the website.
Parameters
Parameters (or query strings) are an optional part of a URL that comes after a question mark (?).

They modify the contents of a page based on the key and value specified.
The key is like a label that says what to change. The value specifies the exact modification criteria.
Let’s use the example URL below to understand this better.

In this example, “category” is the key and “fitness” is the value. This parameter will apply a filter to a webpage to display only fitness-related blog articles.
You can add multiple parameters to a URL by separating them with an ampersand (&).

Now, there are two parameters: “category” with the value “fitness” and “sort” with the value “newest.”
This applies a filter to a webpage to show blog posts about fitness. And displays them from newest to oldest.
For more information about parameters and how to use them on your website, read our full guide to URL parameters.
Anchor
An anchor (also called a fragment identifier) is the optional last part of the URL that takes users to a specific section within a webpage.
It comes after the number (#) symbol.
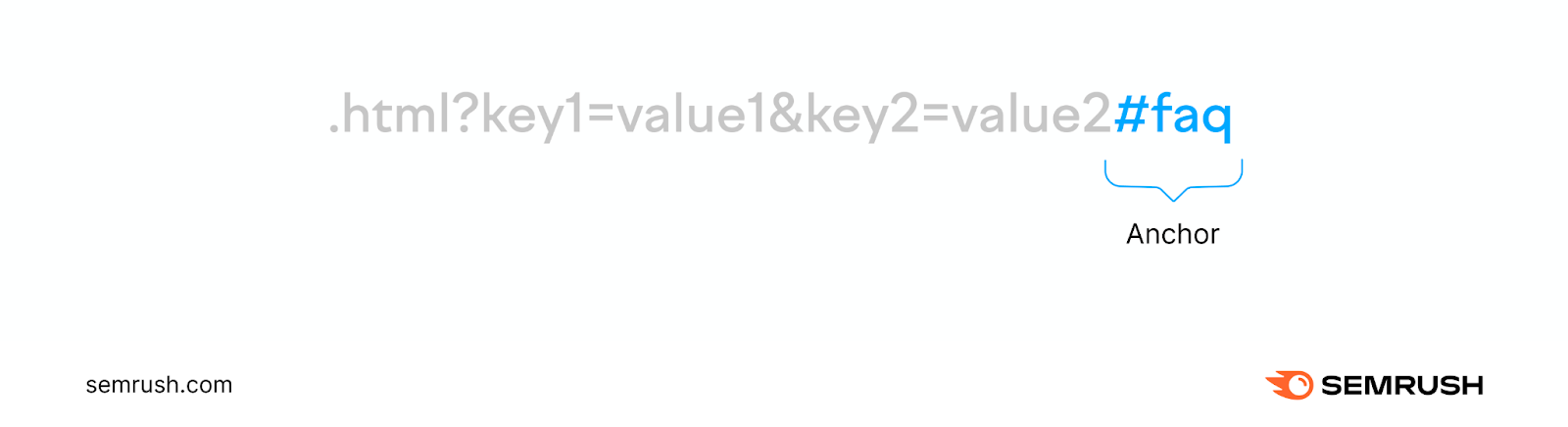
In the example above, the browser will directly scroll to the FAQ section of the webpage rather than opening the webpage at the top.
But anchors aren’t just limited to text content.
For a video or audio file, the browser will jump directly to the time specified in the anchor.
For example, a URL like https://www.example.com/video#t=2m30s will direct the browser to start the video directly at the two-minute and 30-second mark.
What Are Some URL Examples?
Now that you know the components URLs can include, let’s see how combining them can create a wide range of URLs:
http://domain.com/
ftp://ftp.domain.com/downloads/software/setup.exe
https://www.domain.com/news/new-ai-tool
http://www.domain.com/resources.html
mailto:[email protected]
https://domain.com/products/t-shirt/men?color=black&brand=nike
https://domain.com/collection#newlylaunchedAll these URL formats are valid. They point to distinct resources.
And some of them even serve unique functions. Like file management with the FTP protocol and email communication with the mailto protocol.
What Are the Main Types Of URLs?
URLs can be categorized into different types based on their structure and purpose. Here are some common types:
Absolute URLs
An absolute URL provides the complete web address to a resource, including the protocol (like HTTP or HTTPS), domain name, path, and possibly other components like parameters and anchors.
Absolute URLs are commonly used when linking from one website to another. And when sharing links online.
Here are some examples of absolute URLs:
https://www.domain.com/section/science
https://domain.com/wiki/sleep
https://domain.com/products/Relative URLs
A relative URL only specifies the path. Meaning the directory and the slug.
One use case for relative URLs is to link between pages within the same website to create internal links.
This avoids repeating the base domain and protocol in every internal link.
Here are some examples of relative URLs:
documents/report.pdf
archives/article123
blog/what-is-internetURLs are also classified based on the specific purpose they serve. So, let’s look at these types of URLs now.
Canonical URLs
A canonical URL is the primary URL for a set of duplicate URLs on your site.

Duplicate URLs are pages that essentially have the same content.
For example, the same content could be available on:
- https://www.example.com/products
- https://www.example.com/products/
- https://www.example.com/all-products
The canonical URL would be defined as one of those options. Let’s say it’s https://www.example.com/products.
Specifying a canonical URL helps search engines figure out which URL to index (store in its database) and show in search results. (Search engines wouldn’t intuitively know this if duplicate content exists on different URLs.)
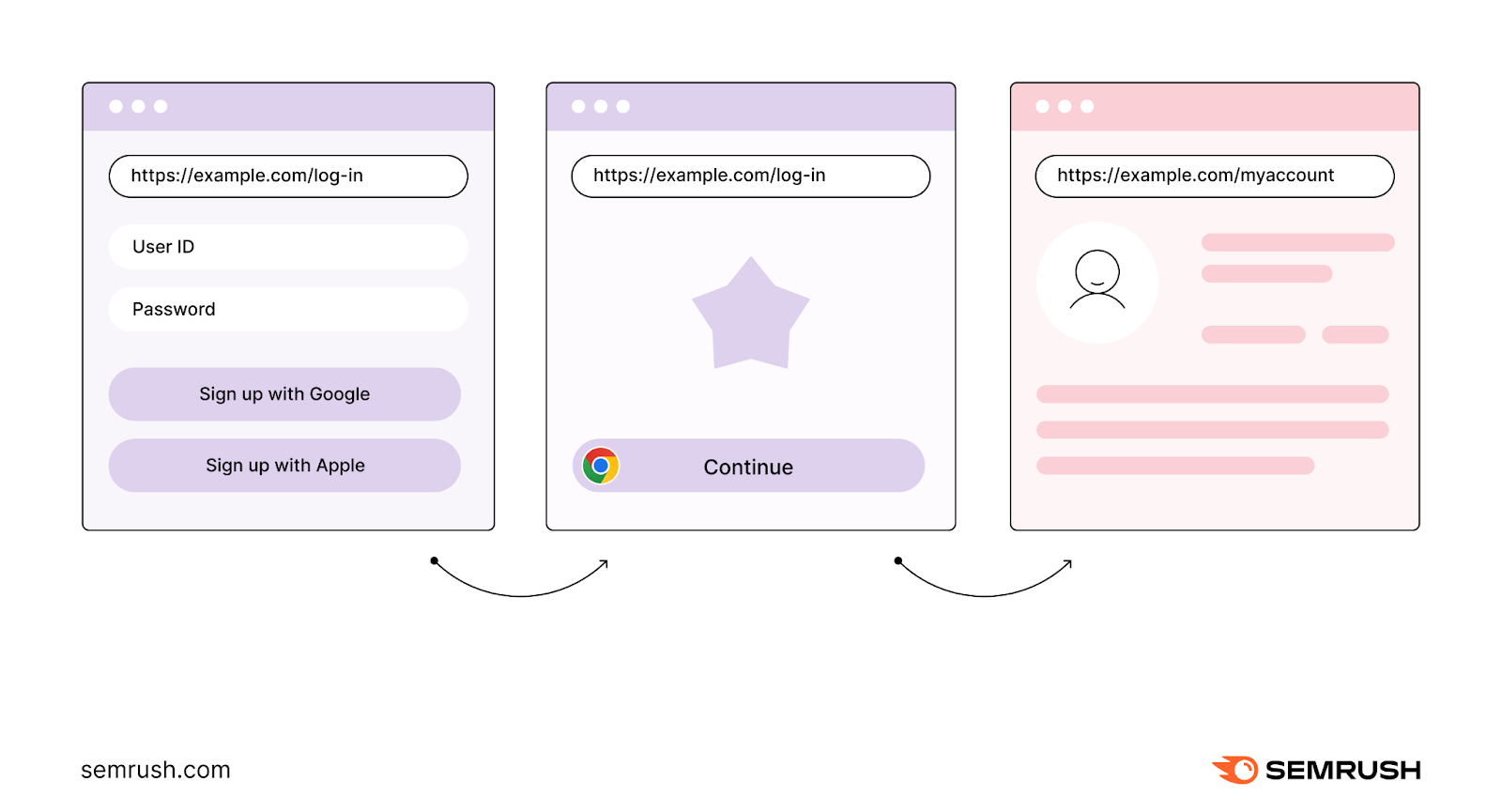
Callback URLs
A callback URL is the page users are automatically redirected to when they complete a specific action or task.
For example, when a user logs in to a website using a third-party authentication service like Google, the page they’re redirected to after successfully authenticating with Google is the callback URL.
Vanity URLs
A vanity URL is a custom URL that is short and easy to share compared to the URLs you normally see.
Vanity URLs are used in marketing campaigns or on social media to promote a specific webpage on your site.
You can use URL shortener tools like Bitly, TinyURL, and Short.io to create them.
Here’re some examples of vanity URLs:
domain.com/sale
domain.io/BestDealsNow
domain.com/discount
domain.org/charityHow to Use URLs
URLs are powerful tools. And you can use them effectively if you understand their role in different contexts, like web browsers, HTML, and other technologies.
Browser
Using URLs in a web browser is the most common way people interact with them. Here’s how:
- Entering URLs: Simply type the URL into the address bar of your browser and press the “Enter” or “Return” key. The browser will then navigate to the specified webpage or resource.
- Bookmarks: You can save URLs as bookmarks in your browser for easy access in the future
- Browsing history: Browsers keep a history of the URLs you've visited, allowing you to easily return to previously viewed pages
HTML
In HTML, URLs are used for:
- Hyperlinks: URLs are used in anchor (<a>) tags to create hyperlinks. These links allow users to click and navigate to other webpages or resources.
- Embedding resources: URLs are used to embed images, videos, and other resources into webpages. For instance, an image (<img>) tag might have a source (src) attribute that contains a URL pointing to an image file.
- Linking CSS and JavaScript: URLs are used to link external CSS files and JavaScript files to HTML documents, enabling you to separate of content, style, and functionality
Other Technologies
URLs also play a critical role in various other technologies. Here are a few common uses:
- Social media: URLs are used to share web content on social media platforms. When you post a URL, many social media sites can fetch and display a preview of the content.
- QR codes: QR codes can encode URLs. When scanned with a smartphone, they direct the user to a webpage, often for marketing or informational purposes.
- Email: URLs are often included in emails to direct recipients to webpages for promotional purposes, user verification (like email confirmation links), to provide further reading, etc.
How to Optimize URLs for SEO
If you want your website URLs to show up in search results and bring traffic to your site, you need to focus on search engine optimization (SEO)
SEO involves optimizing different parts of your website (including your URLs) to rank higher in search engines’ organic (unpaid) search results. Which appear alongside paid results.
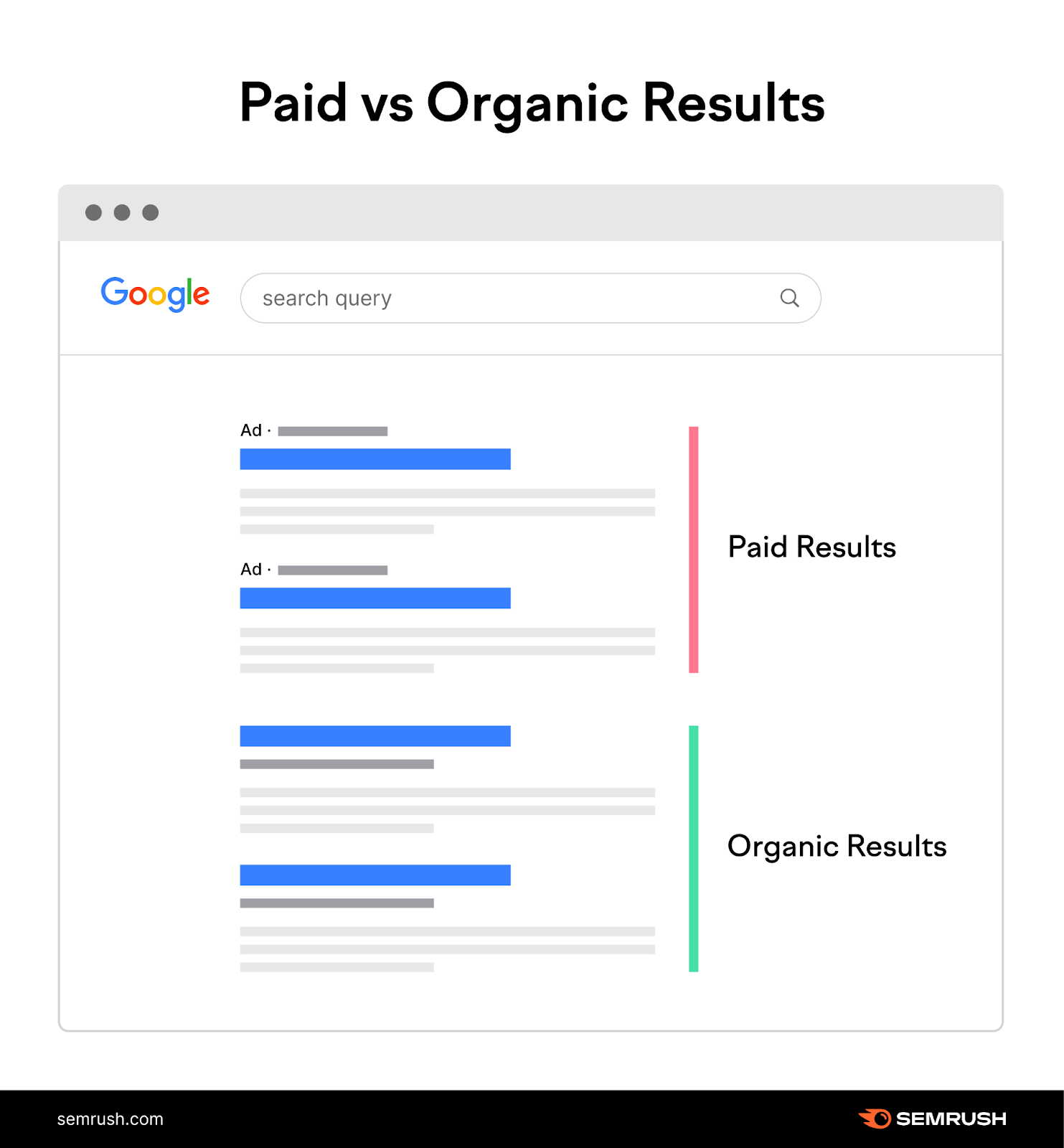
Here are some tips on how to optimize the structure of your URLs.
1. Use the HTTPS Protocol
Since HTTPS is more secure, search engines like Google use it as a light ranking signal.
So if your website uses HTTPS, you have a slight ranking advantage over those who don’t use it.
2. Choose an Appropriate TLD
For the most part, TLDs don’t directly influence your rankings.
But you should use the one that aligns with your business. For nonprofit organizations, .org is best.
For educational institutions, such as universities, colleges, and schools, .edu is the most appropriate TLD.
For commercial websites, .com is the way to go.
If you only do business outside the U.S., your ccTLD( like .au for Australia and .nz for New Zealand) is also fine.
But avoid using TLDs like .info and .biz—people tend to associate these with spam. So you might have a hard time building high-quality backlinks to your site. Which are important to improve rankings.
3. Use Subfolders to Organize Your Content
Use subfolders that logically organize your content and make it easy for users to know where they are on the website.
Which the American Lung Association has done:
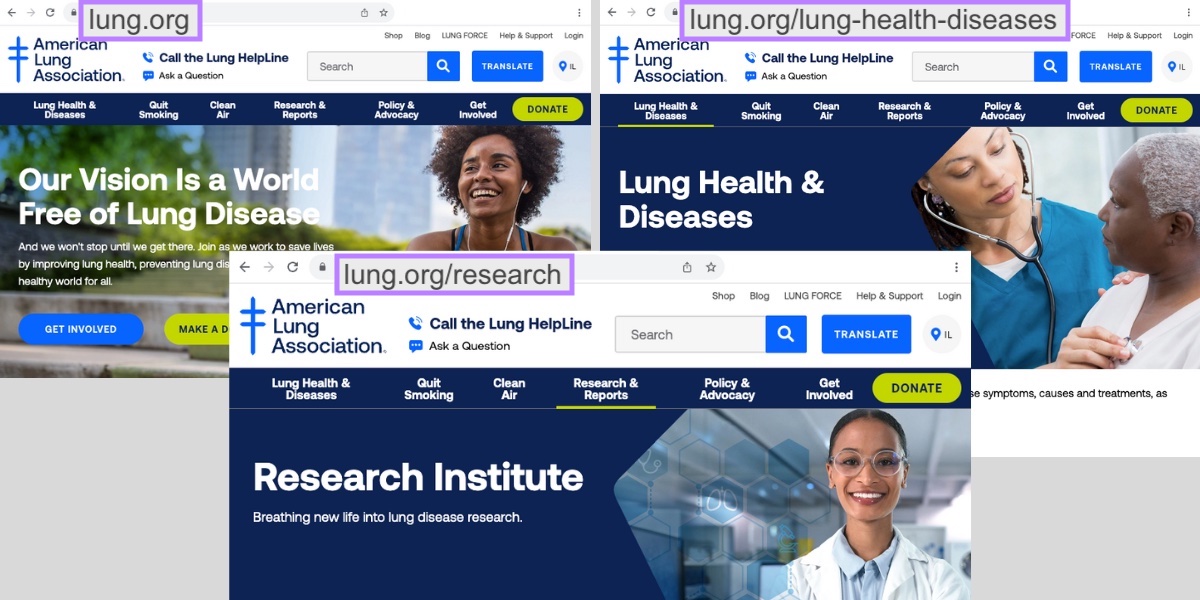
This is important from a user experience (UX) point of view. Which is closely connected to SEO.
Your subfolders should indicate the type of content found at that URL. To help search engines understand your content better.
- Good subfolder: https://website.com/blog/best-travel-tips/
- Bad subfolder: https://website.com/folder1/best-travel-tips/
If you own a really large website—an ecommerce site, for example—it might get tricky to organize all your pages using only one level of subfolder.
In that case, use sub-subfolders to further define your website hierarchy.
Here’s an example of how you could have a subfolder within another subfolder on your site:
https://store.com/men/tshirt/tommy-hilfiger/
4. Optimize Your URL Slugs
You need to do four things to optimize your URL slugs for SEO.
Be Descriptive
Your URL slug should describe the page’s content because it helps the search engine understand what the page is about. And rank it appropriately.
Good URL slug: /best-baby-soaps/
Bad URL slug: /page1234/
The best way to make your URL slugs descriptive is to use the page’s target keyword (the keyword you want to rank for in search results).
If you don’t know what your target keyword is or how to find one, read our guide to keyword research.
Make It Short
Long URLs are harder for users to read. And search engines like Google often truncate long URLs in search results.
Like this:
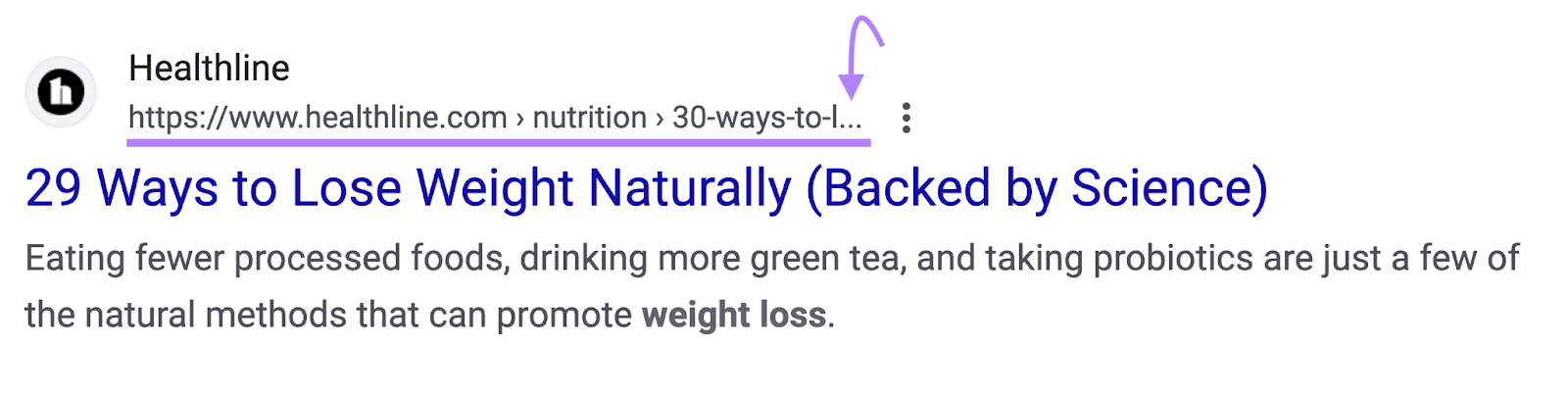
So, try to keep your slugs to five words or fewer.
- Good URL slug: /home-workout-tips/
- Bad URL slug: /the-7-best-home-workout-tips-the-ultimate-cheatsheet-for-training-without-a-gym/
Use Hyphens to Separate Words
Use hyphens to separate words in your URL slug instead of underscores. They're the standard way of separating words in a URL.
- Good URL slug: /free-marketing-tools/
- Bad URL slug: /free_marketing_tools/
Use Lowercase Characters
URLs are case-sensitive. And if you have a particular URL in both lowercase and uppercase, it can create duplicate content issues on your site.
Plus, lowercase URLs make it easier for users to enter the URL correctly.
- Good URL slug: /how-to-make-pizza/
- Bad URL slug: /How-To-Make-Pizza/
Read our full guide to URL slugs for more information.
Audit Your Existing URLs to Identify Issues
If you’re a Semrush user, you can use the Site Audit tool to check whether your URLs are set up correctly. And find any issues that are present.
Create a project in the tool and run a full crawl of your website.
After the crawl is complete, navigate to the “Issues” tab and search for “URL.”

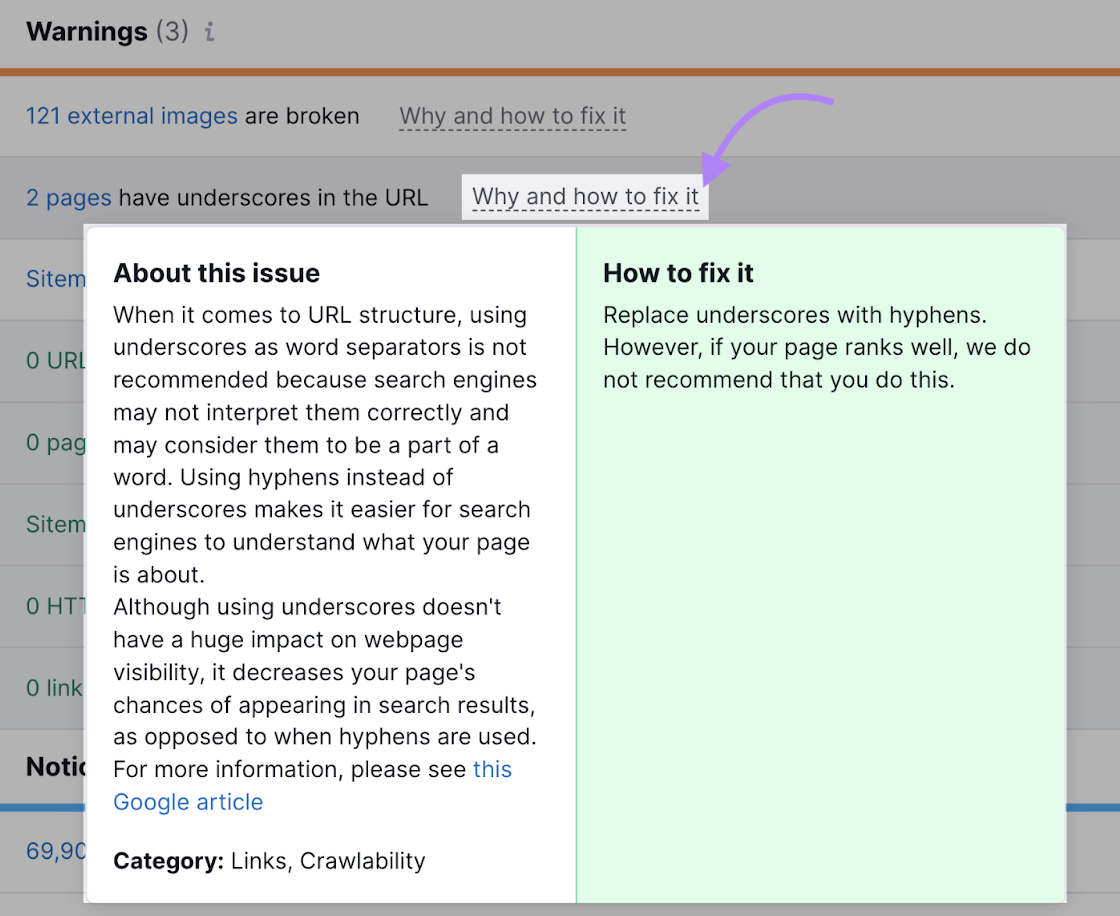
The tool shows whether your website has any URL-specific issues like URLs being too long. Or words in URLs that are separated with underscores instead of hyphens.
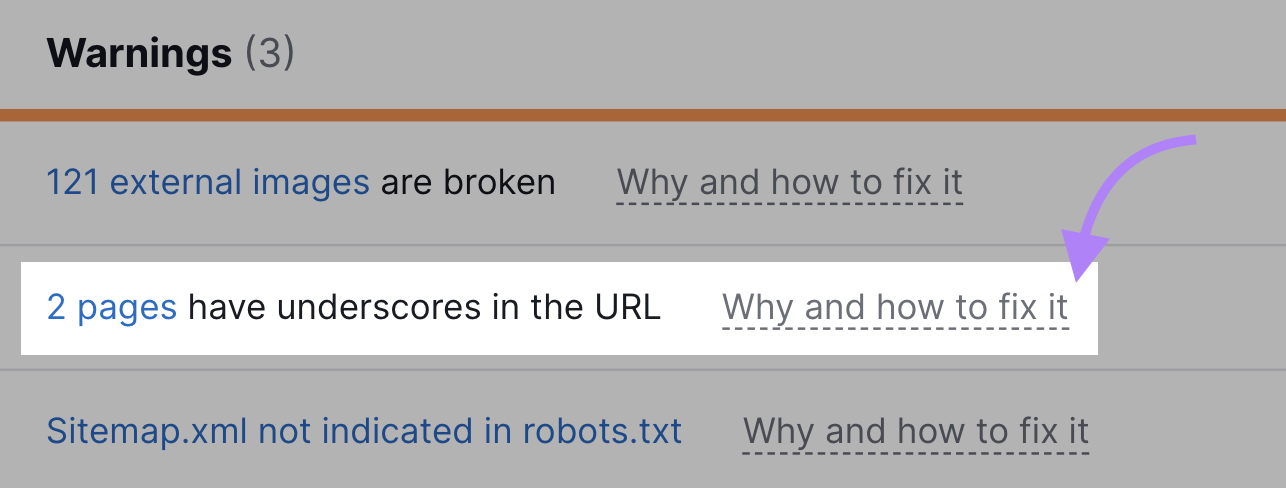
The tool also offers advice on how to fix each issue.
FAQs
To wrap things up, let’s cover some frequently asked questions about URLs.
1. What Does URL Stand For?
URL stands for uniform resource locator. It’s the web address that specifies the location of a resource on the internet.
2. What’s the Difference Between a URL and a URI?
A uniform resource identifier (URI) labels or identifies a resource but doesn't necessarily tell you how to retrieve it.
For instance, isbn:0261103303 identifies the book with that ISBN number but doesn't indicate where or how to get it.
A URL is a specific type of URI that not only identifies a resource, but also provides the means of locating it.
For example, https://www.example.com/page.html is a URL that tells you the resource is the webpage located on example.com’s server at /page.html. And uses the HTTPS protocol to access it.
That’s the main difference.
URLs always point to resources—URIs just name them.
3. Is a URL an IP Address?
A URL is not the same thing as an IP address, which only identifies the domain name.
URLs include additional information like protocols and file paths beyond just specifying the location (domain name).
Multiple URLs can point to the same IP address. But each IP address can only identify one domain.
4. Are URLs Case Sensitive?
The domain name portion of a URL is case insensitive, according to Domain Name System (DNS) standards.
The case sensitivity of other components (path, parameters, anchor, etc.) depends on your web server’s configuration.
To be consistent, treat URLs as case sensitive even if your server allows for mixed cases. And go with lowercase capitalization for all parts of URLs. As it’s the standard way of creating URLs.